Microservices Vs. Apis: Understanding The Key Differences Software Development
Microservices and APIs are not the new terms when architecture and integrations are considered. Both concepts are essential in web application development and design in the present time, and there is surely a connection among their uses. However, it’s significant to identify the differences between the microservices and APIs and how they are employed. This way, you can have more productive discussions with developers and can better understand the applications you utilize and sell.
This blog will look into the differences between both APIs and microservices separately, along with what they do, how they work and why they are required.
What is an API?
API, or application programming interface, is the part of an application that engages with the other applications. An API is a collection of protocols and procedures that define how two applications share and alter each other’s data.
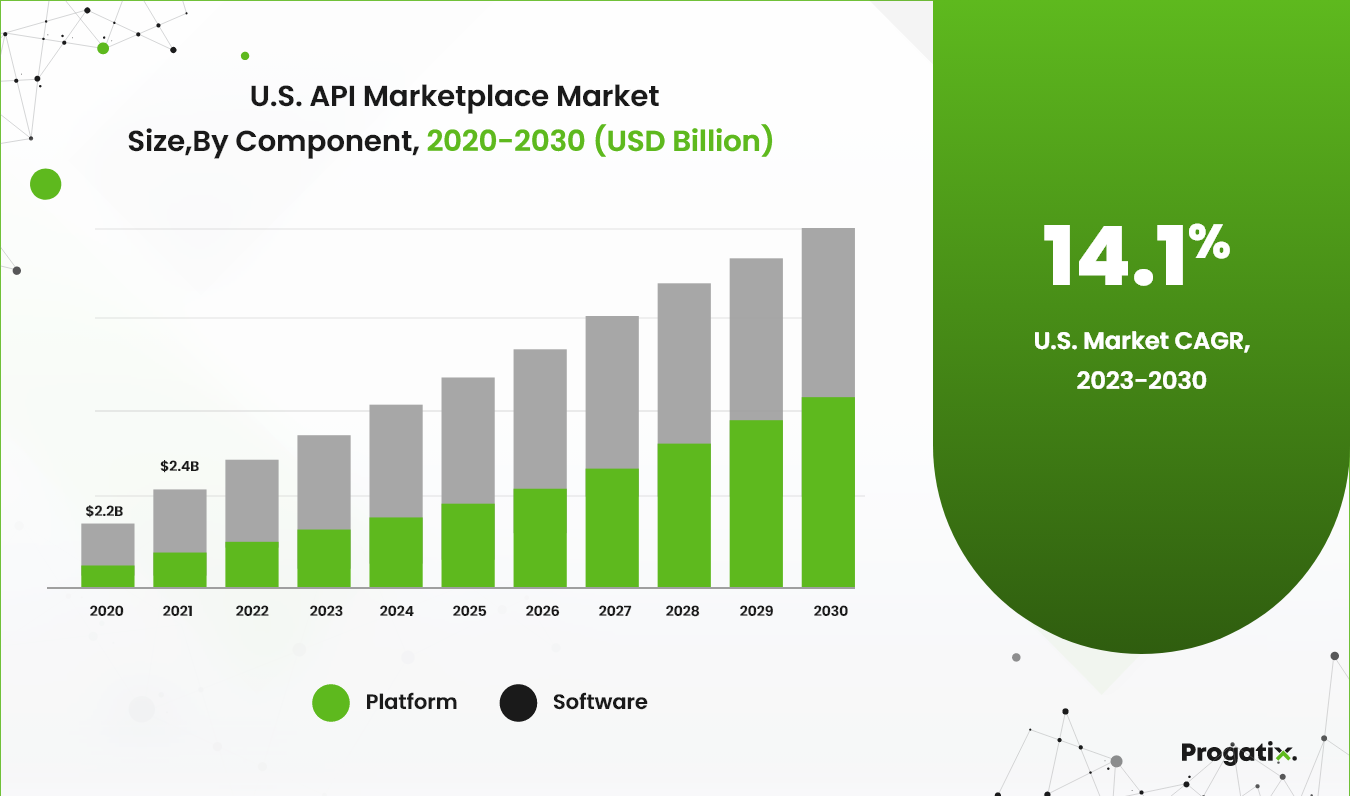
The global API marketplace market size was valued at USD 13.74 billion in 2022 and is expected to grow at a compound annual growth rate (CAGR) of 17.8% from 2023 to 2030. Application Programming Interface (API) marketplaces provide businesses with an easy way to reveal the ideal API that suits their requirements. These marketplaces also offer various features, such as ratings and reviews, allowing businesses to make sure they are choosing a high-quality API.
APIs are required in our present digital infrastructure due to their capability of allowing for standardized and efficient communication between applications that might differ in working and development.
An API collects among a software’s key constituents, and the public and external developers can get access to the definite areas of the application’s backend without needing to understand how everything operates within an app, making an API the interface for programmers.
What are APIs Used For?
If you use software, you use APIs because they allow software integrations. They enable separate software units to share information and work together. Let’s take an example: you are shopping online and ready to check out, and you see that the store you are shopping from offers an option to pay through an XYZ app where you already own an account along with your payment information setup. How easy will it be for you to make a payment through it?
Since the app you are paying through is from a different company from the store you are making a purchase from, an API will help interact between the store and that app. First, the store will use that app’s payment gateway API to request your payment details. Next, the XYZ app’s API screens the request validates it, obtains the information from the customer records, and sends it back to the store. At last, the store utilizes your card details to complete the transaction. Thanks to XYZ, your store gets all the details required to complete your checkout without getting access to that app’s private database itself and without needing you to access the store’s website.
Exchanges like this happen almost at any time when two different applications operate together. Some other real-world instances involve an embedded YouTube video, a travel website utilizing an airline’s API to access flight times and costs, a website utilizing one of Google’s and Facebook’s AIs to enable social login, and a navigation app accessing a public transit system’s API for real-time transference of data.
Different types of APIs
When speaking of APIs, we generally talk about a subdivision of APIs known as web APIs. Web APIs are accessed through the Hypertext Transfer Protocol (HTTP), similar to the protocol utilized for appealing and displaying web pages in browsers.
We can distribute Web APIs into groups based on the projected level of access and scope of use. There are four broadly agreed-upon web APIs:
-
Open APIs
Open APIs are also called public APIs or external APIs. They are accessible to any developer. Open APIs usually have comparatively low authentication and authorization measures and have frequently limited assets they share. While some open APIs are free, others need a subscription fee, which is often ranked based on the number of calls made to the API.
There are numerous advantages to making APIs public, the major being the ability to share data responsively. This inspires any external business or developer to integrate with the app that retains the API, making both the third-party software and the API more useful. Due to the lack of limitations and easy implementation enabled by the open API, third parties can rapidly leverage the data it delivers.
-
Partner APIs
Partner APIs are shared externally, but only between those with a business association with the API Company. Access is restricted to authorized clients with official licenses, and thus, security measures tend to be more robust with partner APIs than with public APIs.
Some businesses support partner APIs because they want
- Better management of who can access their resources.
- More control over how resources are utilized.
For instance, Pinterest app implemented a submission-based approach to offer access to new data services through its API, needing partners to acquiesce to a request specifying how they would like to utilize the API before being offered the access.
-
Internal APIs
In contrast to open APIs and partner APIs, internal APIs, also known as private APIs, are not planned for use by third parties. Internal APIs are only made accessible for use inside a company and are meant to simplify data transfers among teams and systems. Developers working for the company can employ these APIs, but external developers can’t.
Because internal APIs aren’t recognized in a publicly launched software development kit, or at all in some cases, they are usually completely secret from the public. However, many companies do ultimately go public with their internal APIs.
Utilizing APIs for internal data transfers is viewed as more effective, safe, and perceptible. It’s also a scalable solution, when a business announces a new internal system, which can communicate with existing systems through their APIs.
-
Composite APIs
Composite APIs unite numerous APIs, enabling developers to bundle calls or requests and obtain one unified response from diverse servers. If you require data from different applications or data sources, you would utilize a composite API. Otherwise, you can use a composite API to set out an automatic chain of calls and answers without needing your involvement.
Because they decrease the number of total API calls, composite APIs can end in less server load and a whole faster system, providing reduced intricacy in the system. They’re normally deployed in microservices, and one job might need data from several internal APIs to finish.
Types of API Architectures
APIs have their types in terms of their architecture as well. An API’s architecture comprises the rules that direct what information an API can share with clients and how it shares the data. REST, SOAP, and RPC are the most well-known API architectures that are used today. Let us explore each one in more detail.
-
REST
REST also known as representational state transfer is a collection of guidelines for scalable, lightweight and easy-to-use APIs. Today, most of the web APIs are built on REST. A REST API (or “RESTful” API) is an API that adheres to the REST guidelines and is utilized for sharing data from a server to a bidding client. For more details, here are the REST guidelines; see our full guide to REST APIs. Concisely, these guidelines are:
-
Client-Server Separation
All client-server interactions must be in the practice of a request from the client, tracked by a response from the server. Servers can’t request, and clients can’t respond.
-
Uniform Interface
All requests and responses must utilize HTTP as the communication protocol and be organized in a precise way to make sure compatibility remains between any client and any server. Server responses are structured in JavaScript Object Notation (JSON).
-
Stateless
Each client-server interaction is free of every other communication. The server keeps no data from client requests and recalls nothing from past communications.
-
Layered system
Requests and responses must always be formatted in the similar manner, even when distributed through intermediate servers among the client and the API.
-
Cacheable
Server responses must specify whether a delivered resource can be reserved by the client and for how long. By following these guidelines, REST APIs can be utilized for rapid, easy, protected data transfers, making them a preferred choice among developers.
-
SOAP
SOAP (Simple Object Access Protocol) is a protocol for transferring data among networks and can be utilized to build APIs. SOAP is standardized by the World Wide Web Consortium (W3C) and uses XML to encrypt information.
SOAP rigorously outlines how messages should be sent and what they must be composed of. This makes SOAP APIs safer than REST APIs, though the rigid strategies also make them more code-heavy and firmer for devices in general.
For this reason, SOAP is often employed for internal data transferences that need high security, and the more adaptable REST architecture is positioned more commonly everywhere else. But, one more benefit to SOAP is that it operates over any communication protocol (not just HTTP, as is the case with REST).
-
RPC
The RPC (Remote Procedural Call) protocol is the most upfront of the three architectures. In contrast to REST and SOAP, which facilitate the sharing of data, RPC APIs appeal processes. In other words, they implement scripts on a server.
RPC APIs might employ either JSON (a JSON-RPC protocol) or XML (an XML-RPC protocol) in their calls. XML is safer and more cooperative than JSON, but these two protocols are else similar. Though the RPC protocol is rigid, it’s a comparatively simple and easy way to finish code on remote networks.
RPC APIs are restrictive when it comes to security and proficiencies, so you probably won’t see them as often as REST or SOAP APIs on the web. However, it can be utilized for internal systems to generate basic process requests, specifically many at once.
How do APIs Work?
APIs work by transferring data among the applications, systems and devices via requests and response cycle. The request is sent to the API, which collects the data and returns it to the user.
Here is the overview of how APIs work.
API Client
The API client is accountable for beginning the discussion by sharing the request with the API server. The request can be initiated in several ways. For example, a user might initiate an API request by entering a search term or clicking a button. API requests might also be activated by external events, i.e., notifications from another application.
-
API Request
An API request will seem to act differently depending on the sort of API, but it usually comprises the following constituents.
-
Endpoint
An API endpoint is a custom URL that offers access to a particular resource. For example, the article’s endpoint in a blogging app would involve the logic for processing all requests that are associated with the article.
-
Method
The request’s method indicates the kind of operation required by the client would like to execute on a given resource. REST APIs are available via standard HTTP methods, which accomplish common actions like retrieving, creating, updating, and deleting data.
-
Parameters
Parameters are the variables that are passed to an API endpoint to deliver specific instructions for the API to work. These parameters can be involved in the API request as part of the URL, in the query thread, or in the request body. For instance, the articles endpoint of a blogging API might receive a ‘topic’ parameter, which it would utilize to get access and return articles based on a definite article.
-
Request Headers
Request headers are key-value pairs that offer extra details related to the request, i.e., as its content type or authentication permits.
-
Request Body
The body is the main part of the request, and it comprises the actual data that is needed to create, update or delete a resource. For example, if you were creating a new article in a blogging app the request body would possibly involve the article’s content, title and author.
API Server
The API client sends request to the API server, which is held accountable for managing the authentication, validating input data and recovering or operating data.
-
API Response
Finally, the API server shares a response with the client. The API response usually involves the following components.
-
Status Code
HTTP status codes are three-digit codes that specify the result of an API request. Some of the most common status codes involve 200 OK, which specifies that the server successfully returned the requested data; 201 Created, which specifies the server successfully created a new resource; and 404 Not Found, which specifies that the server could not find the requested resource.
-
Response Headers
HTTP response headers are identical to request headers, but they are utilized to offer additional details regarding the server’s response.
-
Response Body
The response body involves the actual data or content the client requested or an error message if something went wrong. To better comprehend this process, it is better to think of APIs like restaurants. In this metaphor, the customer is identical to the user, who asks what she wants from the waiter. The waiter is like an API client, receiving the customer’s order and translating it into easy-to-follow instructions for the kitchen, either using specific codes or abbreviations that only the kitchen staff will understand. The kitchen staff is similar to the API server because it creates the order as per the customer’s preferences and further offers it to the waiter, who then
API Server
The API client sends request to the API server, which is held accountable for managing the authentication, validating input data and recovering or operating data.
-
API Response
Finally, the API server shares a response with the client. The API response usually involves the following components.
-
Status Code
HTTP status codes are three-digit codes that specify the result of an API request. Some of the most common status codes involve 200 OK, which specifies that the server successfully returned the requested data; 201 Created, which specifies the server successfully created a new resource; and 404 Not Found, which specifies that the server could not find the requested resource.
-
Response Headers
HTTP response headers are identical to request headers, but they are utilized to offer additional details regarding the server’s response.
-
Response Body
The response body involves the actual data or content the client requested or an error message if something went wrong.
To better comprehend this process, it is better to think of APIs like restaurants. In this metaphor, the customer is identical to the user, who asks what she wants from the waiter. The waiter is like an API client, receiving the customer’s order and translating it into easy-to-follow instructions for the kitchen, either using specific codes or abbreviations that only the kitchen staff will understand. The kitchen staff is similar to the API server because it creates the order as per the customer’s preferences and further offers it to the waiter, who then delivers it to the customer.
Benefits of APIs
APIs link several software systems, applications, and devices by enabling them to connect with one another. It results in several benefits, ranging from improved user experiences to maximized business productivity. The most common benefit of APIs involves:
-
Automation
APIs can be utilized to automate monotonous, time demanding tasks so that humans can emphasize more complex tasks, improving productivity, particularly for developers and testers.
-
Innovation
Public APIs can be utilized by external engineering teams, which pushes innovation and speeds up development by allowing developers to reprocess existing performance to form new digital experiences.
-
Security
APIs can offer an extra layer of defense against unauthorized breaks by demanding authentication and approval for any request to access critical data.
-
Cost efficiency
APIs provide access to useful third-party tools and infrastructure, which helps businesses escape the costs of building complex in-house systems.
Challenges with APIs
· Getting the abstraction level right is difficult
Either we are marketing rare stamps or any other stamps, or anything significant in apparent form. Anything of value, material or immaterial, it’s easy to see how an API for any of these must assume things in order to be beneficial, or else it would be too vague to be of any value. People are starting to realize that this is more difficult to do than it seems.
-
Real-world systems have real-world glitches
The real world enforces its own rules on us. A very basic example is that in Ireland, it can be difficult to purchase things online from UK-based companies. The rules for this process tend to be arbitrary and can transform rapidly. So if you live in Ireland and are utilizing an API to find cheap flights, for instance, the API might yield entries that are very low but also completely impractical because it adopts you have definite travel permits or are a member of a specific group, or are keen to travel at 0400 on a Wednesday. Trying to model this stuff leads to the problem above, where a too-accurately-defined interface becomes impractical.
-
Existing systems don’t fit into the new API description
Last year’s Mobile World Congress (MWC) was joined by a number of vendors offering API space. One of the major issues for large, recognized vendors is that they already have current systems that could be really, really hard to fit into the public APIs, excluding important extra work and loss of functionality.
-
Political forces at play with their own plans
Because of the inactivity existing systems create, their owners have potential inducements to push the structure of the API and align it with their legacy codebase. This can lead to a ‘camel-is-a-horse designed-by-committee’ situation, where the following API is more a consideration of engaging political wills than practical common sense.
-
Writing the API doesn’t mean you’ve written the application
This is possibly the biggest issue. People are so fixated on completing and modifying the API that they don’t get around to distributing usable code almost fast enough. Given that the two most significant words in software are ‘done’ and ‘finished,’ this is a problem. And while the APIs define contracts for what gets approved back and forth, we usually don’t deliberate projected interruption or accessibility.
What is Microservice?
A microservice is a form of software architecture that distributes an application’s diverse functions into smaller mechanisms known as ‘services.’ When an application is developed this way, it is called a ‘microservice architecture.’
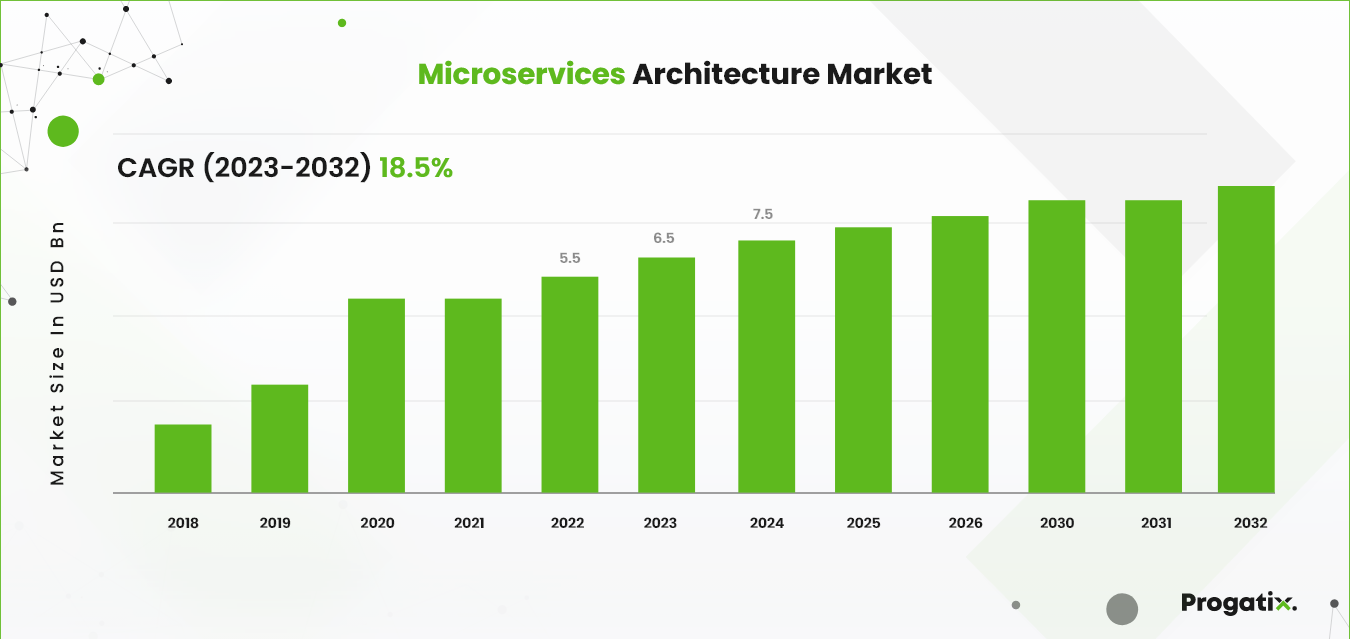
Microservices Architecture Market Size was estimated at USD 6.5 Billion in 2023. The Microservices Architecture industry is anticipated to grow from USD 7.7 Billion in 2024 to USD 30.0 Billion by 2032, exhibiting a compound annual growth rate (CAGR) of 18.5% during the forecast period (2024 – 2032).
The microservice architecture for an application can consist of individual services for user account management, integrations with online dealers and user authentication. Each service operates like its own small components of software within the larger system.
Each service within the wider microservices owns to perform one operation, but the scope of these tasks is up to the app’s developers. A basic software application might depend on a few services. In the case of huge software enterprises, an application might contain hundreds of granular services with highly precise functions.
Why Use a Microservice Architecture?
To comprehend why a microservice architecture is valuable for software developers, first its predecessors need to be comprehended, which is the monolith.
A monolith application is the opposite of a microservice. Instead of allocating diverse tasks to different self-sufficient services, every operation of the application is controlled by a single program.
While it may make sense to begin developing an application this way, why worry about building numerous programs. Users of the monolith will run into problems when the abilities and complexities of their application expand. When every feature of an application has been integrated into one program, managing updates, identifying issues, allocating responsibilities to developers, and understanding the code in general becomes challenging.
Simply, everything is so linked within the monolith that it can be difficult to unravel, creating a need for a new type of architecture, hence the upsurge of microservices. Compared to a monolith, the microservice architecture enhances.
Streamline your architecture with our Microservices Development Services.
Contact Progatix Now!
Let's Connect-
Updates
In a microservice application, updating individual services doesn’t need alteration of the whole system. This saves time, cost, and mending effort, besides allowing to list updates as opposed to rare major updates.
-
Simplicity
A developer doesn’t have to comprehend the whole system architecture to learn about one aspect of the software.
-
Team organization
Microservices outline restrictions between developer responsibilities. DevOps teams can be allocated to one or more microservices instead of some share of a nebulous or indefinite monolith.
-
Security
If one service cooperates, it (ideally) won’t impact any other service directly.
-
Robustness
Likewise, if one service is disrupted, other services are unhurt.
-
Flexibility
If a team needs to build a service a specific way (e.g. with a different language or structure), they don’t need to be concerned regarding how this may influence other operations. To combine everything by separating responsibilities, microservices advance and streamline the software development process. However, a suite of isolated modules won’t make much of a difference for an application, which is why these services are connected together by the APIs.
How do microservices work?
To understand where it all begins from, knowing about the benefits of microservices architectures is important.
-
Monolithic applications
Originally, each application, based on a single server, contained three layers:
- Presentation
- Application/business logic
- Database
These layers were built in a single, interweaved stack positioned on a single, monolithic server in a data centre. This arrangement was common throughout every industry vertical and technology architecture. Normally, an application is a suite of code modules that serve a particular purpose for instance, a database, numerous types of business logic, graphics rendering code, or logging.
In this monolithic architecture, users cooperated with the presentation layer, which communicated to the business logic layer and the database layer, and details then travelled back up the stack to the end user. Though this was an effective way to build an application, it created several single points of failure, which could end up in long outages if there was a hardware failure or code bug. Unluckily, “self-healing” did not occur in this structure. If a part of the system was impaired, it would require to be fixed by human interference in the form of a hardware or software fix.
Additionally, scaling on any one of these layers meant buying an entire new server. You had to purchase a monolithic application working on a single server and divide a share of users over to the new system. This sectioning resulted in user data in cellars that had to be resolved by nightly batch reports. Luckily, client needs became lean as webpages and mobile applications became more known, so new methods of application development started to take shape.
-
Service-oriented architecture (SOA)
By the mid-2000s, the architectures started to alter so that numerous layers existed outside a single server and as self-regulating service silos. Applications were intended to integrate these services by utilizing an enterprise service bus for communication, an approach allowing administrators to independently scale these services by combining servers through proxy proficiencies. The approach also allowed for shorter development cycles by allowing engineers to emphasize only one part of the application service structure. Decoupling services and enabling independent development need the use of APIs, the set of syntax rules that services use to connect with each other.
SOAs also overlapped with the increase of the virtual machine (VM), which made physical server resources more effective. Services could be deployed much faster on smaller VMs than preceding monolithic applications on bare-metal servers. With this grouping of technologies, better high-availability (HA) solutions were advanced, both within the services architecture and with the related infrastructure technologies.
At present, cloud microservices break down the SOA strategy further as a group of granular functional services. Collections of microservices merge into large microservices, offering the even greater capability to rapidly update the code of a single function in an inclusive service or larger end-user application. A microservice aims to address a single issue, such as a data search, logging function, or web service function. This approach maximizes flexibility, for instance, updating the code of a single function without having to reorganize or even relocate the rest of the microservices architecture. The failure points are more self-regulating of each other, creating an overall steady application architecture.
This approach also generates a possibility for microservices to become self-recovering. With orchestration tools i.e., Kubernetes, self-recovering can happen without human interference. It happens behind the scenes, is automatic, and is visible to the end user.
Microservices architectures have come into use along with Docker containers, a packaging and deployment construct. VM images have been utilized as the deployment mechanism of choice for several years. However, containers are even more effective than VMs, enabling the code (and required code libraries) to be deployed on any Linux system (or any OS that supports Docker containers). Containers are the seamless deployment vector for microservices. They can be activated in seconds and redeployed quickly after failure or migration. They can scale rapidly to fulfill their needs. Because containers are innate to Linux, commodity hardware can be implemented to wide farms of microservices in any data center, private cloud, or hybrid multi-cloud.
Microservices have been entangled with cloud-native architectures almost from the start, so they have become vague from each other in several ways. Because microservices and containers are so distant, they can work on any accordant OS (usually Linux). That OS can occur anywhere: in the public cloud, on-premises, in a virtual hypervisor, or even on bare metal. As more development is completed in the cloud, cloud-native architectures and practices have transferred back into on-premises data centers. Many organizations are building their local environments to share the same basic features as the cloud, allowing a single development practice throughout any location or cloud-native anywhere. This cloud-native approach is made thinkable and required by the adoption of microservices architectures and container technologies.
Key differences: Microservices vs. APIs
Both microservices and APIs are significant tech stacks that help firms build and scale applications. Microservices are the building blocks of an application. Each service usually comprises a database, data access layer, business logic, and API. APIs involve programming information, including data format, data exchange expectations, and protocols.
They support distributed development in diverse ways.
-
Purpose
The microservices architecture intends to enhance software development efficiency by dividing a large code block into numerous smaller services. This way, several developers can work on different microservices concurrently based on decided conditions.
The API, in the meantime, links different functions or services within or outside an application. The range of internal APIs is restricted to a single application. A public API can be utilized to access open-source functionality irrespective of which programming languages and tools they were built on.
-
Types
Microservices are largely categorized into stateful and stateless. Stateful microservices recall their past outcomes when they practice current requests, while stateless microservices don’t recall past memories.
Concurrently, APIs are characterized by audience, architecture, and protocol. For instance, developers use the following types of APIs when they build applications: private, public, partner, microservices, composite, SOAP, and REST APIs.
-
Security
Microservices offer you more control over data security and accessibility, as they are developed and controlled by your internal team. Whilst, APIs may or may not be safe depending on who writes the code after them and what data they require. So the developers must be careful while using external APIs.
-
Debugging
Microservices are challenging to debug due to their distributed architectural style. Moreover, individual microservices might be advanced with different programming languages and frameworks and connect in an irregular pattern, confusing the developer’s efforts to reproduce the error state, track data movement, monitor programming variables, and recognize the root cause. Unlike the microservices architecture, it’s more forthright to debug APIs. Developers can take a step-by-step approach to perceive the API behavior and detect the key concern.
Benefits of Microservices
-
Agility
An organization made up of independent, small teams that own their services is encouraged by microservices. Teams usually function in constrained, extensively researched contexts and have the strength to work faster and more freely. Development cycle times are reduced by this. The organization’s overall productivity offers significant advantages to you.
-
Adaptable Scaling
With the use of microservices, a service can scale easily to please the needs of the application feature it provides. This makes it feasible for teams to properly estimate the needs for infrastructure, estimate the cost of a feature, and assure availability in the event that demand for a service rises.
-
Easy Deployment
Microservices allow for continuous integration and continuous delivery, making it easy to test new ideas and to cut if something doesn’t work. The low cost of failure enables experimentation, makes it easier to update code, and accelerates time-to-market for new features.
-
Technological Freedom
Microservices architectures don’t follow a “one size fits all” approach. Teams have the liberty to choose the best tool to tackle their specific issues. As a result, teams building microservices can select the best tool for each task.
-
Reusable Code
Dividing software into small, well-defined modules allows teams to use functions for multiple purposes. A service written for a definite function can be utilized as a building block for another feature, enabling an application to bootstrap itself, as developers can create new capabilities without writing code from scratch.
-
Resilience
Service independence maximizes an application’s struggle to failure. In a monolithic architecture, if a single component fails, it can cause the whole application to fail. With microservices, applications manage total service failure by demeaning functionality and not failing the whole application.
Challenges with Microservices
-
Service Communication
If you have worked in a real world Microservice architecture then you might know that Microservices depend profoundly on inter-service communication, which can become a difficulty as the number of services increases. With each service having its own API and protocols, handling communication becomes difficult.
-
Data Management
Data management throughout microservices can be complex due to the decentralized nature of the architecture. Varying data models and preserving data consistency pose challenges.
-
Distributed Tracing and Monitoring
When requests span many services, microservices applications become highly challenging to monitor and troubleshoot. Traditional monitoring instruments may not provide adequate visibility.
-
Service Orchestration and Choreography
Microservices can be orchestrated centrally or choreographed in a decentralized way. Both methods have their challenges. Orchestrating services might lead to a single point of failure, while choreography can end in improved complexity and challenges in tracking the flow.
-
Deployment and DevOps
The deployment of Microservices includes managing multiple service examples while ensuring consistency across different settings. It’s almost impossible to deploy Microservice in the traditional way.
-
Testing across Services
Testing Microservices is not easy at all and needs comprehensive strategies due to the complex nature of their connections. Traditional unit testing might not be necessary.
-
Security and Access Control
Microservices can reveal several endpoints, maximizing the potential attack surface. For the most part, you will not even be aware of this but no need to worry, almost all huge organizations have vast security teams with fat pay to bother you.
-
Scalability and Resource Allocation
Scalability is a core potential of microservices and one of the main drivers for several companies to discard monoliths in service of Microservices, but it needs careful planning. Some services may experience heftier loads than others, leading to resource allocation challenges.
-
Versioning and Compatibility
As Microservices progress individually, maintaining backward and forward compatibility becomes important, as incompatible alterations can disturb the whole system.
-
Organizational Complexity and Communication
Microservices architecture can reflect an organization’s structure, leading to challenges in communication and collaboration, such as diverse teams managing diverse microservices. It’s vital that Cross-functional teams operating on different services align their efforts.
The Future (and Present) of Software Architecture
Over the past decade, leading software companies such as Amazon, Netflix, and Spotify have implemented the microservice approach. Though their implementations are a bit more complex, the fundamental principle is the same: Splitting an application’s tasks into software constituents, making everything streamlined and more effective, and connecting all of it together.
If your organization is generating or updating its software infrastructure, it helps to comprehend these ideas. To this day, APIs and microservices are reforming not just how software works collectively, but how people engage as well.
Suppose you’re looking for a reliable software development partner to improve your microservices and API strategies, look no further than Progatix, which offers innovative and cost-effective solutions for deploying, managing, and securing microservices and APIs in the cloud. Our expertise allows organizations to move beyond traditional software architectures and embrace modern web applications with ease. Through our support, you can deploy and scale microservices-based applications smoothly while maintaining robust API management for ideal performance and security. Get in touch with Progatix today to transform your cloud infrastructure and boost your application development.


 Let's Discuss Your Tech Solutions
Let's Discuss Your Tech Solutions 






