MongoDB Best Practices – A Complete Developer’s Guide Web Development

MongoDB is the leading NoSQL document database for contemporary developers employed on high-performance applications. With its JSON-like documents, MongoDB is important for horizontal scaling and corresponding load, offering developers an exceptional balance of scalability and customization.
According to simplywallst, revenue from MongoDb surpassed analyst approximates by 7.2% back in 2023. Earnings per share (EPS) also exceeded analyst estimates by 60%. Further, revenue is estimated to grow 19% p.a. on average during the next three years, probably up till 2026, associated with a 9.7% growth forecast.
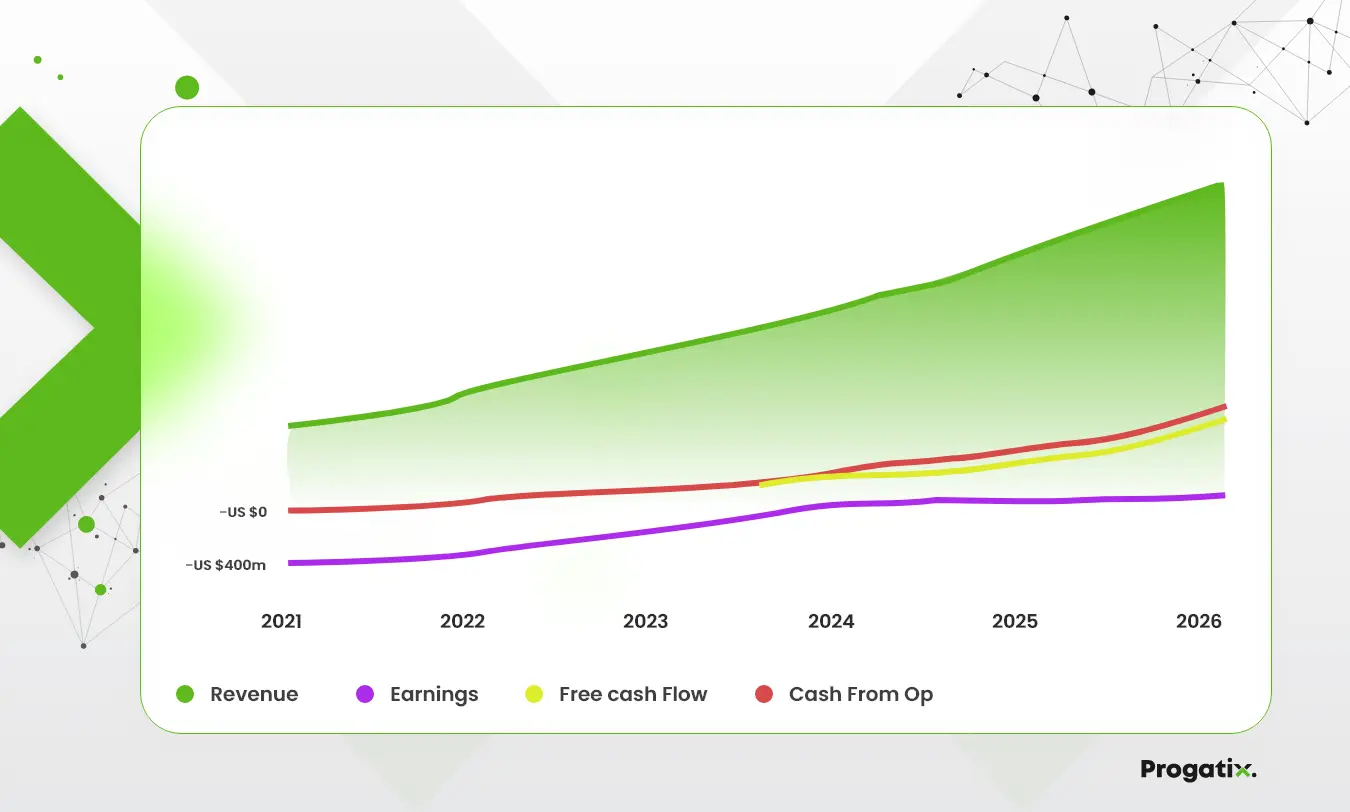
Source: simplywall
But like any high-performance tool, MongoDB executes best in the hands of an expert who knows what they’re doing. Performance issues might specify that the database is not operating as hard as it could and that precise optimizations can lead to better performance.
This blog will look at some crucial techniques that can be applied to make the most of MongoDB for your applications.
- Data modeling and indexing
- Query patterns and profiling
- Embedding and referencing
- Sizing memory
- Replication and sharding
First, look at MongoDB basics.
Basics
MongoDB is a non-relational document database providing support for JSON-like storage. Its adaptable data model enables you to effortlessly store unstructured data. First launched in 2009, it is the most frequently used NoSQL database. It has been downloaded more than 325 million times.
MongoDB is common with developers because it is easy to initiate. Over the years, MongoDB has announced several features that have evolved the database into a robust solution and allowed it to store terabytes of data for applications.
However, as with any database, developers and DBAs operating with MongoDB must look at ways to optimize their database performance, particularly these days with cloud services, where each byte managed, conducted, and stored costs money. When working with MongoDB, a software development company Dallas trusts can help ensure that the capability to get started quickly does not lead to overlooking potential problems or missing out on simple performance enhancements.

MongoDB Best Practices
1. Enable authorization and authentication on your database right from the start.
The larger the database, the greater the damage from a leak. There have been plentiful data leaks due to the modest fact that authorization and authentication are restricted by default when installing MongoDB for the first time. While it is not a presentation tip, it is important to allow authorization and authentication right from the beginning, as it will save you any possible pain in the coming time from any unauthorized access or data leakage.
When a new case of MongoDB is arranged, the instance has no password, user, or access control by default. Recently, in MongoDB versions, the default IP binding was transformed to 127.0.0.1, and a localhost exception was included, which condensed the perspective for database disclosure while installing the database.
However, this is still not decisive from a security viewpoint. The first bit of advice is to generate the admin user and resume the instance again by enabling the authorization option. This prevents any unapproved access to the instance.
2. Don’t use ‘not recommended versions’ or ‘end-of-life versions’ in production instances and stay updated.
It is apparent, but one of the most shared issues we observe with production instances is caused by developers operating a MongoDB version that is actually not appropriate for production in the first place. This might be due to the version being out of date, i.e., with an outdated version that needs to be updated to a newer renewal containing all the essential bug fixes.
Or it might be due to the version being too prompt and not yet tested sufficiently for production use. Developers are usually profound to use our tools’ up-to-date and supreme versions. We also want to be reliable over all the development stages, from early build and test through to production, as this reduces the number of variables we have for support, the prospective for issues, and the cost to succeed in all of our instances.
For some, this could mean utilizing versions that are not retained for production deployment yet. For others, it could mean speaking with a definite version that is tried and trusted. This is a matter of concern from a troubleshooting viewpoint when an issue is firm in a later version of MongoDB that is accepted for production but has not been deployed yet. Alternatively, you might overlook the fact that the database instance is “just working” in the background and miscue when you require to implement a patch.
While it might be enticing to stick with one version, charging up with advancements is crucial to avoid problems in production. You might want to take the lead on newly added features, but you must put these features via your test process first. You want to see if they cause any concerns that might impact on your overall performance before taking them into production.
Finally, you must check the MongoDB Software Lifecycle Schedules and forestall the advancements of your clusters before each version’s life ends. End-of-life versions do not accept bug fixes, patches, or any kind of enhancements. This can vacate your database instances through exposure and susceptibility.
From a performance viewpoint, getting the right version of MongoDB for your production applications contains being “just right.” It’s not so near the draining edge that you will happenstance bugs or other concerns, but also not so far behind that you will lose out on dynamic updates.
3. Use MongoDB replication to ensure HA and check the status of your replica often.
A replica set is a set of MongoDB procedures that preserves the same data on all of the nodes used for an application. It offers termination and data accessibility for your data. When you have various copies of your data on diverse database servers, or even better, in different data centers around the globe, replication offers a high level of fault forbearance in case of any disaster.
MongoDB replica sets operate with one writer node, also called the primary server. The best practice commendation always has to have an odd number of members. Traditionally, replica sets have at least three instances:
- Primary (writer node)
- Secondary (reader node)
- Secondary (reader node)
All of the replica set’s nodes will work collaboratively, as the primary node will obtain app server writes, and then the data will be emulated to the secondaries. If something occurs to the primary node, the replica set will select a secondary as the new primary. To make this process work, besides ensuring a streamlined failover, it is significant for all the nodes of the replica set to have the same hardware configuration. Another benefit of the replica set is that it has the potential to guide read operations to the secondary servers, progressing the database’s read scalability.
After you deploy a replica set to production, it is significant to check the replica’s health and the nodes. MongoDB has two significant commands for this determination:
- Rs. status () offers information related to the replica set’s current status, utilizing data resulting from the heartbeat packets guided by the replica set’s other members. It’s quite a useful tool for examining all node’s status in a replica set.
- Rs. printSecondaryReplicationInfo() offers an organized report of the replica sets status. It’s very valuable to check if any of the secondary ones are behind the primary ones on data replication, as this would impact your ability to retrieve all your data in the event of something going wrong. If the secondary is too far behind the primary, then you can lose a lot more data than you are contented with.
However, keep in mind that these commands offer point-in-time information rather than unremitting monitoring of your replica sets health. In a real production setting, or if you have several clusters to form, running these commands could become time-consuming and annoying. Therefore, using a monitoring system like Percona PMM to observe your clusters is recommended.
4. Use $regex queries only when necessary and choose text search instead where you can
Occasionally, the simplest way to search for something in a database is to employ a regular expression or $regex operation. Numerous developers select this option, but in fact, using regular jargon can harm your search operations at scale. Therefore, you should evade the use of $regex queries, specifically when your database is wide-ranging.
A $regex query devours a lot of CPU time, and it will generally be enormously slow and incompetent. Generating an index doesn’t help much, and occasionally, the performance is poorer with indexes than without them.
For instance, let’s run a $regex query with a collection of 10 million documents and utilize explain (true) to observe how many milliseconds the query takes.
It’s common to observe or test a new application using $regex operations for search demands. This is because neither the developers nor the DBAs perceive any performance concerns in the establishment when the collections’ size is small, and the application users are very few.
However, when the collections become higher, and the application collects more users, the $regex operations begin to hold back the cluster and become terrifying for the team. With time, as your application scales and more users need to perform search requests, the level of performance can drop considerably.
Rather than using $regex queries, use text indexes to upkeep your text search. Text search is more proficient than $regex but obliges you to add text guides to your data sets beforehand. The indexes can involve any field whose value is a thread or a collection of string elements. A collection can have merely one text search index but can cover numerous fields.
To complete, if you can resolve the query using text search, do so. Restrict $regex probes to those use cases where they are really essential.
5. Think wisely about your index strategy.
Putting some consideration into your queries at the beginning can gradually have an enormous impression on performance. First, you need to comprehend your application and the kinds of queries that you are supposed to process as a part of your service. On this basis, you can form an index that assists them.
Indexing can help speed up read queries, but it brings with it an extra storage cost, and it will slow down write operations. Accordingly, you will need to think about which fields must be listed so you can escape creating too many indexes.
For example, if you are forming a compound index, subsequently, the ESR (Equality, Sort, Range) rule is necessary, and using an index to categorize the results enhances the query’s speed.
Likewise, you can always test if your queries are really utilizing the indexes that you have generated with. explain(). At times, we perceive a collection with indexes already formed, but the queries either don’t use the indexes or rather use the wrong index completely. It’s significant to create only the indexes that will actually be utilized for the read queries. Having indexes that will never be used is a remaining of storage and will hold up write operations.
Lastly, if. explain() shows you that a specific query is using a wrong index, you can exert the query to use a specific index with. hint(). Calling the. hint() method on a query leads to MongoDB’s default index selection and query optimization procedure, allowing you to identify the index that is utilized or to carry out an onward collection or reverse collection scan.
6. Check your queries and indexes frequently.
Every database is exclusive and specific to its application, and so is the way it develops and alters over time. Nobody knows how an application will advance over months and years or how the queries will alter. Whatever expectations you have, your anticipations will predictably be wrong, so it is important to check your database and indexes frequently.
For instance, you might plan a definite query optimization approach and a particular index but apprehend after one year that a few queries are consuming that index, and it’s no longer required. Being persistent with this approach will cost you more in storage while not offering any enhancements in application performance.
On that account, it’s essential to perform query optimizations and observe the indexes for each collection regularly. MongoDB owns some tools to perform query optimization, including the database profiler or the. explain() method. It is recommended that they be used to finding which queries are slow, besides knowing how queries use indexes and where you might need to bring betterment in the optimizations. Additionally, to eradicate indexes that are not used proficiently, beware of duplicate indexes that you don’t require for running.
Here, you might be considering how many results you want to or must get from a query, as offering too many results can affect performance. Sometimes, you only require the first five query results rather than tens or hundreds of responses. In such cases, the number of query results can be limited with .limit().
Another beneficial approach is to utilize projections and get only the required data. If you necessitate only one document field, use a forecast instead of recovering the entire document and then filter on the app side.
Finally, if you want to order the query results, be sure that you are using an index and getting help to improve your productivity.
7. Don’t run multiple mongod or mongos instances on the same server
Even if it has the potential to operate multiple Mongod or Mongod instances over the same server, utilizing diverse procedures and ports, it is strongly recommended not to do it.
When multiple Mongod or Mongos processes are run over the same server, it becomes quite tough to screen them and the resources they are using (CPU, RAM, network, etc.). Therefore, when there is a concern, it becomes enormously challenging to observe what is going on and get to the root cause of the concern.
We have come across several cases where customers have practiced a resource problem on the server, but because they are operating multiple instances of Mongod or Mongos, they do not even realize which precise process has the most challenging problems. This makes troubleshooting the problem exceptionally challenging.
Likewise, in some cases where custom software developers have executed a sharded cluster to measure up their application data, multiple shards are experienced running on the same server. In these situations, the router will send numerous queries to the same node, overfilling the node and leading to poor performance, which is the exact opposite of what the sharding strategy desires to accomplish.
The worst-case scenario here includes replica sets. Suppose running a replica set for flexibility and accessibility and then determining that two or more members of the replica set are working over the same server. This is a method for disaster and data loss. In comparison to application designed for durability, you will have made the entire deployment more likely to fail.
8. Back up frequently
So, you own a cluster with replication, but you want to sleep better? Run your data backups habitually. Regular backups let you restore the data from the start if you need to mend from an unexpected event.
There are numerous diverse options for backing up your MongoDB data:
- Mongodump / Mongorestore
Mongodump reads data from MongoDB and generates a BSON file that Mongorestore can utilize to populate a MongoDB database. These offer effective tools for supporting and helping small MongoDB dispositions. On the positive side, you can pick a particular database or gather to corroborate proficiently, and this approach doesn’t need to stop node writes. However, this approach doesn’t hold up any indexes you have generated, so when renovating, you would want to redevise those indexes yet again. Logical backups are, in general, leisurely and time-consuming, so you would have to factor that time into your re-establishment process. To conclude, this method is not suggested for sharded clusters that are more intricate deployments.
- Percona Backup for MongoDB
Percona Backup for MongoDB is an open-source, isolated, and low-impact solution for reliable backups of MongoDB sharded clusters and replica sets. It allows Backups for MongoDB servers, replica sets, and sharded clusters. It can assist physical, logical, and point-in-time retrieval backups and backups to any place containing AWS S3, Azure, or filesystem storage types. However, it does involve preliminary setup and configuration on all the nodes that you would want to shield.
- Physical / file system backups
You can form a holdup of a MongoDB deployment by creating a copy of MongoDB’s fundamental data files. You can utilize diverse methods for these backup types, from physically copying the data files to Logical Volume Management (LVM) snapshots to cloud-based snapshots. These are frequently faster than logical backups, and they can be imitated or united to distant servers. This approach is particularly suggested for huge data sets, and it is suitable when building a new node on the same cluster.
On the shortcoming, you cannot choose a precise database or gathering when reinstating, and you cannot do incremental backups. Additionally, operating a committed node is commended for captivating the backup as it needs halting writes, affecting application performance.
9. Know when to share your replica set and choose a shard key carefully
Sharding is the most challenging architecture you can locate with MongoDB. As your database advances, you will be required to increase the capacity of your server. This can include counting more RAM, more I/O capacity, or even more potential CPUs to manage processing. This is termed vertical scaling.
However, if your database raises so much that it outdoes the volume of a single machine, then you might have to divide the workload up. There are numerous reasons that might lead to this. For example, there might not be a physical server vast enough to manage the workload, or the server instance would cost so much that it would be prohibitive to run. In such situations, you must begin deliberating about horizontal scaling.
Horizontal scaling includes dividing the database over numerous servers and counting additional servers to maximize capacity as essential. For MongoDB, this process is called sharding, and it depends on a sharding key to manage how workloads are parted across machines.
Selecting a sharding key might be the most challenging task you will come across while managing MongoDB. It’s required to examine the datasets and queries for future planning before selecting the key due to its exertion to relapse the shard once it has been agreed on. For MongoDB 4.2 and previous versions, conveying a shard key is a one-way process that cannot be unfinished. For MongoDB 4.4 and advanced, it is possible to improve a shard key, while MongoDB 5.0 and above let you alter the shard key with the Reshard collection command.
If you select a bad shard key, then a huge percentage of documents might go to one of the shards and only a few to the alternative. This will make the sharded cluster unsteady, which will impact performance gradually. An unsteady cluster typically occurs when a key that progresses uniformly is selected to shard a collection, as all the files over an agreed value would go to one shard instead of being dispersed equally.
Besides observing the value used to shard data, you will also be required to think about the queries that will take place over the shard. The queries must utilize the shard key so that the Mongos process allocates the queries over the sharded cluster. If the query doesn’t utilize the shard key, then Mongos will lead the query to cluster every shard, impacting the performance and making the sharding strategy unproductive.
10. Don’t throw money at the problem.
Last but not least, it’s common to see teams tossing money at the concerns they have with their databases. However, as an alternative to directly attaining the credit card, the first attempt is to think sidewise and visualize a better solution.
Counting more RAM, including more CPU, or proceeding to a wider instance or a bigger machine can overpower a performance problem. However, doing so without first analyzing the underlying problem or the blockage can lead to more of the same kinds of problems in the future. In most cases, the answer is not consuming more money on resources but looking at how to optimize your implementation for better performance at the same level.
Although cloud services make it easy to scale up instances, the inefficiency costs can rapidly get higher. Eviler, this is a continuing expense that will be conveyed over time. Viewing areas like query optimization and performance first is likely to evade further spending. For some of the customers we have driven with, the aptitude to demote their EC2 instances protected their companies’ huge amount of money in monthly charges.
As a general recommendation, approve a cost-saving approach and, before accumulating hardware or griping up cloud instances, take your time to examine the problem and ponder upon a better solution for a prolonged time.

 Let's Discuss Your Tech Solutions
Let's Discuss Your Tech Solutions 






